
Based on Docker and the Kubernetes container cluster manager, Red Hat OpenShift is the next generation container platform for developing, deploying and running containerized applications conveniently and at scale. In this article, Chris Morgan (@cmorgan_cloud), Technical Director for OpenShift Ecosystem, and Martin Etmajer (@metmajer), Technology Lead at the Dynatrace Innovation Lab, discuss why OpenShift and the Dynatrace digital performance management solution are a perfect combination. The interview is led by Franz Karlsberger (@fraka7), Director Strategic Partners, at Dynatrace.

Franz: Chris, great to have you with us today. Can you explain to our readers what OpenShift is about and what makes it stand out in the container platform world?
Chris: The best way to describe it is that Red Hat OpenShift is a complete container application platform that provides all aspects of the application development process in one consistent solution that can span across multiple infrastructure footprints — public/private cloud, virtualization and bare metal. Our goal is to help you get your next big idea to market before your competition by offering flexibility for your business and application frameworks.
Franz: How do you see the traditional roles of development and operations change with the use of a container platform like OpenShift?
Chris: With OpenShift, developers have the freedom to build, ship and run their containerized apps from a selection of predefined, customized and hardened images, which are provided to them by the platform operators. This removes traditional barriers of responsibility, reduces friction and vastly improves productivity for everyone involved. In short, we let coders code, while operations can manage and automate.
Franz: We’ve seen a lot of buzz around OpenShift recently. How would you describe your customers and which offerings do you make available to them? What’s the best way to getting started?
Chris: We have customers across all verticals utilizing all of our services today. You can see a good number of them at https://www.openshift.com/customers. We offer three commercial flavors of OpenShift — OpenShift Container Platform (runs on infrastructure of your choice), OpenShift Online (multi-tenant, cloud-based service) and OpenShift Dedicated (single-tenant, cloud-based service). For an individual developer, a great way to start is with our OpenShift Online environment (still in Developer Preview, currently). This will allows users to understand the development flow on our platform.
Franz: Martin, containers are closely related to microservice architectures. Which pros and cons do you see when embracing this new, promising approach to software engineering?
Martin: In principle, in line with the UNIX philosophy, microservices should be designed to “do one thing and do it well”. This leads to systems composed of small, simple and modular components which can be developed, deployed and scaled often and independently.
So, when starting with microservices, one of the first question that comes up is “What should go into a service?” and “What’s the right size?”. After all, when the word “micro” in “microservices” is taken too literally, as in “A microservice should be 100 lines of code or less.”, you’ll only end up in a distributed, nevertheless tightly coupled, system of microservices that exhibits unhealthy communication behaviors.

Franz: That is interesting. Can you elaborate on that?
Martin: Sure! When moving from monolith to microservices, you are trading fast in-memory communication for slower inter-service communication across networks. Typically, data from multiple services are needed to support a single business functionality. For example, a product overview page may require data points related to users, products, pricing, availability, reviews, and more. Sadly, remote calls across networks are slow.
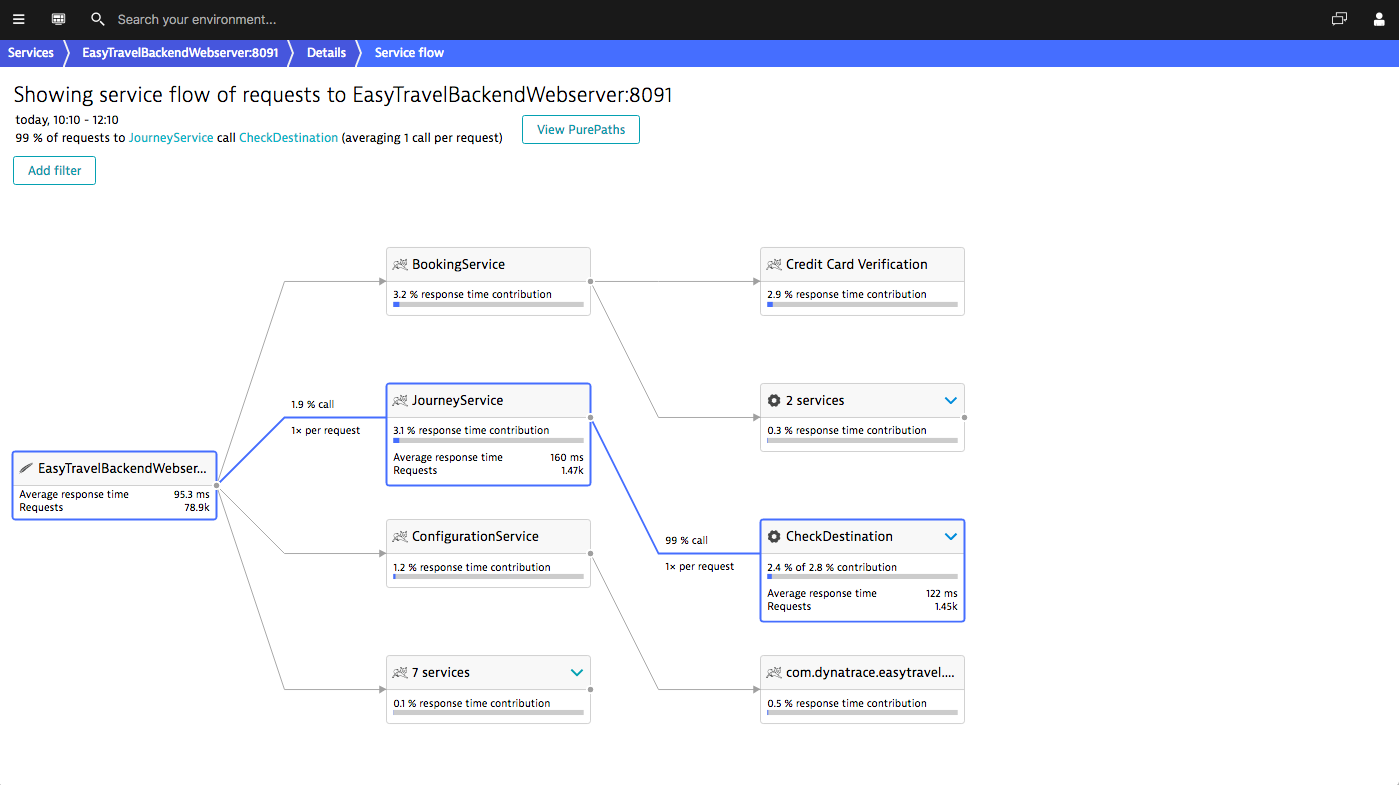
So here is my suggestion: while service size matters to maintain simplicity and modularity, the term “microservices” overly emphasizes the size of services. Instead of making “micro” or even “nano” your primary design goal, put equal priority on designing robust, well-defined interfaces, which exhibit healthy communication behavior. At large, “babbling” services can be your primary source of performance issues.
Franz: Sounds like there are a couple of pitfalls to expect down the road which could be avoided. Can you tell us more?
Martin: ThoughtWorks brought up the term microservice envy when referring to companies who rushed into adopting microservices without understanding the right level of granularity and the complexities involved. We’ve also learned in the past that highly dynamic, distributed systems such as microservices demand better monitoring, which is why we’ve built Dynatrace in the first place. If you want to learn more about the complexities behind microservices, please take a look at our OpenShift Commons Briefing on “Monitoring Microservices at Scale on OpenShift with Dynatrace”.
Franz: Chris, Dynatrace is an OpenShift Primed partner and an active participant in the OpenShift Commons community. What does Dynatrace bring to the table?
Chris: Beyond years of industry knowledge in the APM space, Dynatrace offers one of the best solutions I’ve seen for monitoring applications running on OpenShift. What really distinguishes them from others is the use of artificial intelligence based root-cause analysis. OpenShift is a platform to allow you to run decoupled services and applications, which can be a monitoring nightmare, but Dynatrace’s insights makes it less scary.
Franz: This question goes to you, Martin. How can our readers get started with Dynatrace on OpenShift?
Martin: Let me emphasize again that Dynatrace is available for all OpenShift environments — no matter if you’re running in a private, public, shared or dedicated context. For more information on getting started on OpenShift Container Platform, please refer to our article on “Monitoring OpenShift Apps with Dynatrace” (also featuring Ansible) on the OpenShift Blog. When using OpenShift Dedicated or OpenShift Online, where access to the cluster nodes is inhibited, please refer to “Monitoring OpenShift Apps with Dynatrace (for PaaS)”.
Franz: Is there anything else you’d like our readers to know?
Chris: As Martin mentioned, whether you are an enterprise developer, enterprise operator, application engineer — or just a hobbyist — with Dynatrace and OpenShift, there is a combination of solutions that can fit your needs, and I’m personally excited to see our partnership continue to evolve.
Martin: If you are interested in trying us out, sign up for the Dynatrace free trial! And if you have any questions, suggestions or feedback, please don’t hesitate to reach out to me directly. I’ll be happy to answer your questions and share further insights.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum